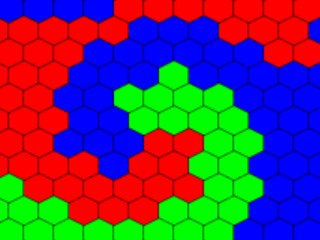
As the GameDev.tv Game Jam gives participants a free course, I figured I had to do something with this Jam. The theme of the jam was “Life in 2 Dimensions” so my immediate thought came to Conway’s game of Life. Life is a cellular automata simulator with a set of very simple rules for running that results in surprising results. My first change was to place the automata on a hex grid. I then added three types of life and set the rules so Red cells eat Green cells which eat Blue cells which eat Red cells. My idea was that I would have levels where you would place cells in such a way that your color would dominate the board. I also made the decision to write the game entirely from scratch.
What Went Right
The actual simulation aspect game together quickly and my preliminary test showed that it worked producing a rather interesting swirling effect. While the simulation is fun to play with for short bursts, and random mode makes rather interesting displays, by itself it is not really a game. My idea for a game was to have the player control one of the colors and attempt to turn the board entirely that color. This, will be discussed in the what went wrong section.
Mixed Blessings
The decision to do the game from scratch was a good one considering I am planning to build a game engine from scratch so this would be good practice. I had not anticipated as much interruption from the real world as there was but it was good practice getting back to building everything. Had I gone with my own libraries, I would have been able to do a bit more polish on the game but as things stand it doesn’t look too bad the way that it is. While eating up a bit more time than I would have liked, creating the UI from scratch let me play around with different, and better, techniques than I have in my rather dated and overly simple SLL libraries. This will be helpful as I get further along in the book series I am working on.
What Went Wrong
While the sim as it stands has nice flashy displays, it is not quite enough to allow for good strategic design. I am sure that there are additional features and rules that could be added to allow for more strategy allowing for a challenging game, but that is not here. Unfortunately, the way the rules work make for a fairly easy way for finding solutions to win the game. I am undecided if I will revisit this game but with more rules and other features to increase the challenge of the game but that is certainly a possibility.
Final thoughts
I have been reneging on this blog, so I am thinking about taking my code for the game and cleaning it up going over the code and what I am doing to improve it. This would also result in some soapbox posts about a variety of topics. I'm not sure how often I am going to update this but may go to a fortnight format where I update my book on Spelchan.com in one week and then post about my refactoring on this blog. I may also consider entering more game jams, depending on what my schedule is going to be like.